
CTO perspectives | Blog Post
Context Engineering Is the New Bottleneck
Natalie Fagundo
Share this post
Every developer on your team can prompt a model. Context engineering is what separates the ones who ship AI that works in production from the ones who don’t. That’s the new table stakes.
The engineers who move fast — who ship AI features that actually work in production — are doing something different. They’re engineering context: deciding what information the model sees, when it sees it, and how it’s structured. That’s the work. And most engineers aren’t trained for it.
At some point soon, if it hasn’t happened already, you’re going to hit a wall. Not because the models aren’t good enough. Not because your engineers aren’t using them. Because the information those agents operate on — the documentation, the ownership records, the system metadata — is wrong, stale, or too noisy to be useful. And no model, however capable, can compensate for that.
What Context Engineering Actually Is
Prompting is asking a model a question. Context engineering is deciding what the model needs to know to give you a useful answer — and building the systems that deliver it reliably.
That means retrieval architecture, structured memory, tool selection logic, and prompt pipelines that hold up under load. It means understanding where models fail and why — not just tweaking wording until something works.
The difference shows up in production. A well-prompted feature demos well. A well-engineered context layer ships and stays shipped.
It’s not prompt engineering. Prompt engineering is one input among many, and it doesn’t scale past the individual developer. Context engineering is what a platform team builds so that every agent across the organization operates on accurate, current, well-scoped information, without each engineer solving that problem from scratch.
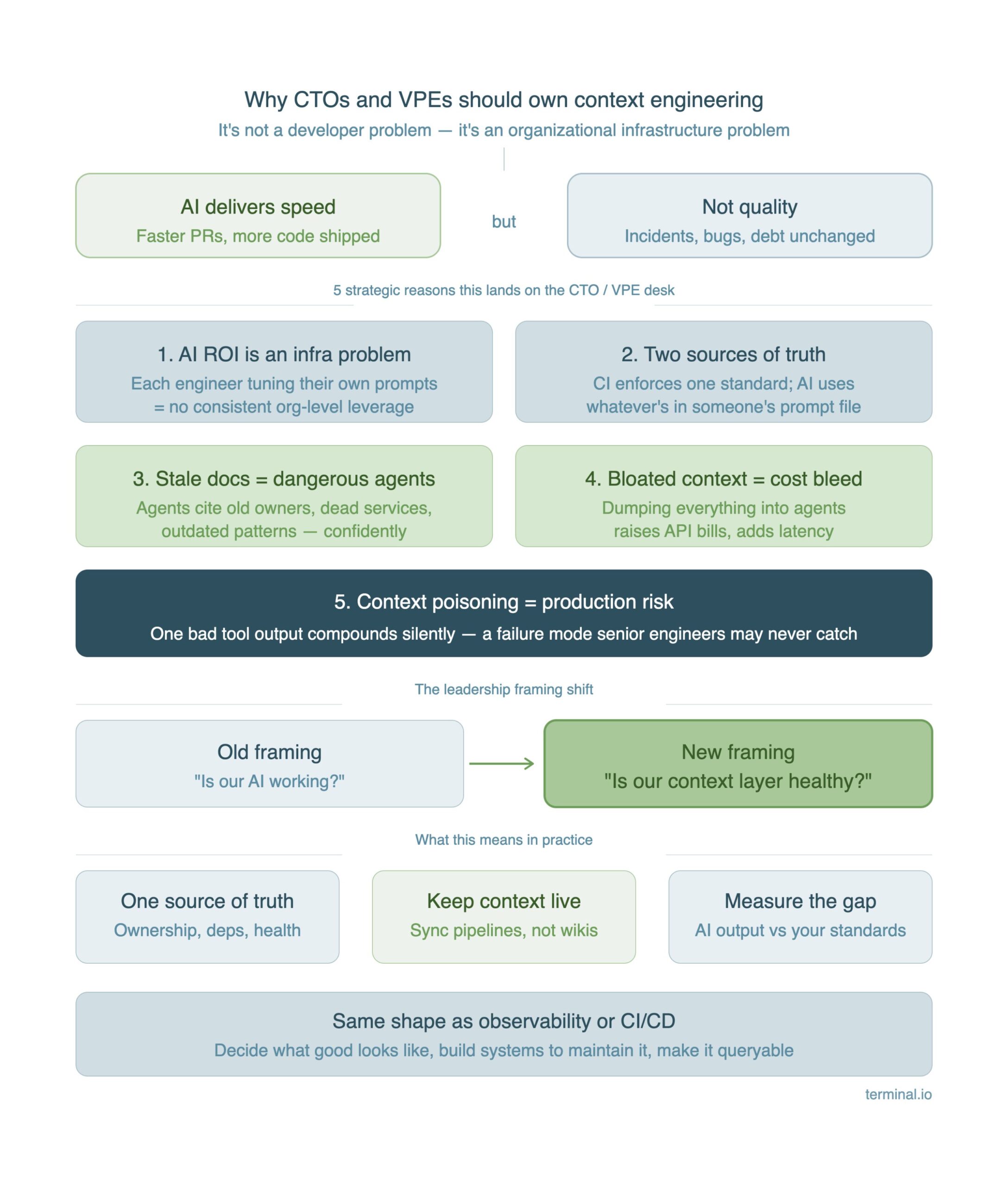
The teams getting real, compounding leverage from AI have figured this out. They’ve stopped asking “is our AI working?” and started asking “is our context layer healthy?” — treating the answer with the same seriousness they bring to observability or CI/CD.
Why Context Engineering has Become a Bottleneck
AI tooling has outpaced the engineering workforce. Models are capable. The constraint is the engineer who knows how to deploy that capability at scale.
Three things create the gap:
1. Most AI training is prompt-level, not systems-level. Courses teach developers to get better outputs from a single query. They don’t teach how to design the retrieval system that feeds the model, manage token budgets across a multi-step pipeline, or build evals that catch failures before users do.
2. Context engineering requires depth, not just familiarity. You need engineers who understand embedding models, chunking strategies, vector stores, and how context window constraints interact with latency requirements. That’s not a weekend certification. It’s hard-won experience.
3. The engineers who have it are already employed — and selective. Senior AI-fluent engineers know their market value. They’re not responding to inbound recruiting. And they can tell within 10 minutes of a technical screen whether your team is worth joining.
The Hiring Signal you Should be Paying Attention to
At Terminal, we’ve had a front-row seat to how engineering leadership priorities have shifted, and the change in hiring briefs over the past year has been abrupt, not gradual.
For a long time, the requests we received were specific and stable: senior backend, Python, distributed systems. Then, almost overnight, those briefs changed. As Dylan Serota, Terminal’s CEO, and Paolo Bettoni, VP of Engineering at Digible, discussed in a recent webinar on AI maturity: engineering leaders stopped asking for specific coding skills and started asking for engineers who “really know how to use AI.”
That first shift has already happened across most of the organizations we work with. The second shift is just beginning, and it’s more consequential. The engineering leaders asking the sharpest questions right now aren’t asking whether a candidate uses AI tools fluently. They’re asking whether a candidate can build the systems that make AI reliable at scale. That’s a meaningfully different hire. And it’s the one the context engineering era demands.
What AI fluent Engineers Actually Look Like
Terminal screens every active candidate against our AI Fluency Standard, a structured assessment of how engineers use AI in real workflows — not a checkbox. 80% of our active engineering pool has completed the evaluation.
The results tell a clear story about where the global engineering talent pool actually stands:
- 87% are AI Enabled or AI Native. They’ve moved past using AI for suggestions and are actively orchestrating agents, navigating unfamiliar codebases, and shipping faster as a result.
- 49% are AI Native — the highest tier: engineers who direct parallel agents, maintain deep system ownership, and architect the kind of context layers that make AI reliable at scale.
- 30% have both an AI fluency rating and shipped AI-powered products — meaning they’ve shipped something real with AI, not just passed an evaluation.
This is the talent profile context engineering requires. Not an engineer who uses Copilot well. An engineer who can build the infrastructure that makes every AI tool in your org more reliable.

Three Questions Worth Asking your Team
You don’t need a full audit to know whether context engineering is a gap in your organization. These three will tell you most of what you need to know.
- How often do your agents cite information you know is outdated? If the answer is “sometimes” or “I’m not sure,” your context layer has a freshness problem. Agents don’t flag stale inputs. They reason from them confidently.
- Do all your engineers operate from the same AI standards, or does it depend on who you ask? If individual developers are maintaining their own prompt files and context rules, you have as many standards as you have engineers. That’s not a productivity layer. It’s technical debt in a new form.
- When an AI-assisted workflow produces a bad output, can you trace why? If the answer is no, you don’t have visibility into your context layer. You’re flying blind on a system that’s increasingly making consequential decisions.
If any of these land, context engineering isn’t a future concern. It’s a current one.
The Model is a Commodity. The Context Layer is your Edge.
If your AI initiatives are stalling — pilots that don’t graduate to production, features that work in demos but not at scale — the gap is probably here. The fix isn’t more prompting workshops. It’s headcount with the right depth: engineers who’ve shipped context-aware systems, who’ve debugged retrieval failures at 3am, who understand the tradeoffs between latency, accuracy, and cost in a live product.
Every engineering team has access to the same frontier models. That’s not where the competition is anymore. The organizations that pull ahead are the ones that build and staff the information infrastructure those models depend on. Teams that get this right scale their AI roadmaps. Teams that don’t spend quarters on pilots.
The model isn’t your bottleneck. The engineer who knows how to use it is.
Terminal’s AI Fluency Standard identifies engineers who can build that layer, not just ship with the tools on top of it. Browse AI fluent talent today!
